
Table of Content
Que son los datos abiertos u opendata?
Los datos abiertos son datos que pueden ser utilizados, reutilizados y redistribuidos libremente por cualquier persona, y que se encuentran sujetos, cuando más, al requerimiento de atribución y de compartirse de la misma manera en que aparecen.
Dicha atribución, normalmente esta ligada a una licencia de uso o explotación que define que cosas puedes hacer con ellos y si tienes que dar algun tipo de autoria. Algunas de las licencias de explotación más comunes que se podrán encontrar son:
- MIT: Esta licencia es una Licencia de software libre permisiva lo que significa que impone muy pocas limitaciones en la reutilización y por tanto posee una excelente Compatibilidad de licencia.
- Apache: La licencia Apache (Apache License o Apache Software License para versiones anteriores a 2.0) es una licencia de software libre permisiva creada por la Apache Software Foundation (ASF).8 La licencia Apache (/ əˈpætʃi/) (con versiones 1.0, 1.1 y 2.0) requiere la conservación del aviso de derecho de autor y el descargo de responsabilidad, pero no es una licencia copyleft, ya que no requiere la redistribución del código fuente cuando se distribuyen versiones modificadas.
- Creative Commons: Las licencias Creative Commons (CC) son una herramienta legal de carácter gratuito que permite a los usuarios (licenciatarios) usar obras protegidas por derecho de autor sin solicitar el permiso del autor de la obra.
Caracteristicas de los datos abiertos
- Disponibilidad y acceso: la información debe estar disponible como un todo y a un costo razonable de reproducción, preferiblemente descargándola de internet. Además, la información debe estar disponible en una forma conveniente y modificable.
- Reutilización y redistribución: los datos deben ser provistos bajo términos que permitan reutilizarlos y redistribuirlos, e incluso integrarlos con otros conjuntos de datos.
- Participación universal: todos deben poder utilizar, reutilizar y redistribuir la información. No debe haber discriminación alguna en términos de esfuerzo, personas o grupos. Restricciones “no comerciales” que prevendrían el uso comercial de los datos; o restricciones de uso para ciertos propósitos (por ejemplo sólo para educación) no son permitidos.
¿De qué datos estamos hablando?
La clave es que cuando se trata de abrir datos el foco se pone en información no personal, es decir, datos que no contienen información sobre individuos específicos. De manera similar, para algunos tipos de datos gubernamentales, pueden aplicar restricciones nacionales de seguridad.
Caso de uso Bilbobus
Ahora que ya conocemos el concepto de datos abiertos, veamoslo mejor con un ejemplo más ilustrativo. En este caso, he elegido el caso de uso de Bilbobus.
¿Que es Bilbobus?
El servicio municipal de transporte urbano de Bilbao, Bilbobus que cuenta en la actualidad con 44 líneas, 27 líneas convencionales, 9 Auzolineas y 8 Gautxoris, transportó el pasado año a casi 16 millones de personas. La flota de Bilbobus la componen 141 autobuses, y el servicio cuenta con 525 paradas en todo Bilbao, lo que supone que el 99,8% de la población tiene una a menos de 300 metros.

A través de la empresa Biobide, que desde 2012 es la encargada de ofrecer este servicio, Bilbobus se ha convertido en un referente de movilidad en la ciudad, consiguiendo año tras año una alta valoración entre los usuarios y usuarias.
En la actualidad la flota cuenta con 11 vehículos 100% eléctricos, y una unidad más se incorporará a lo largo de 2021; además, 60 unidades híbridas han ido sustituyendo a los vehículos de combustión, lo que muestra el compromiso del servicio con el Medio Ambiente y la sostenibilidad.
La apuesta de Bilbobus por los vehículos eléctricos forma parte de su compromiso con el medio ambiente, la sostenibilidad, y la búsqueda de soluciones para reducir el impacto de esta actividad en el medio ambiente. De los 148 vehículos de la flota que se mueven con combustible, 106 lo hacen con BIO 10 %.
Bilbobus está compuesta por una plantilla formada por 625 personas que trabajan cada día por ofrecer a la ciudadanía un servicio de transporte público de máxima calidad y para todos.
Encontrando los datos abiertos sobre Bilbobus
En este caso, los datos abiertos relacionados con el Ayuntamiento de Bilbao y sus diferentes servicios se encuentran disponibles en la página https://www.bilbao.eus/opendata/es/inicio. Desde allí, se puede acceder a los diferentes datos publicados con su información asociada.

Gracias al buscador incorporado, o haciendo una busqueda en Google, podremos encontrar datasets que nos interesan. En la búsqueda que yo he realizado, se muestran 22 resultados encontrados.
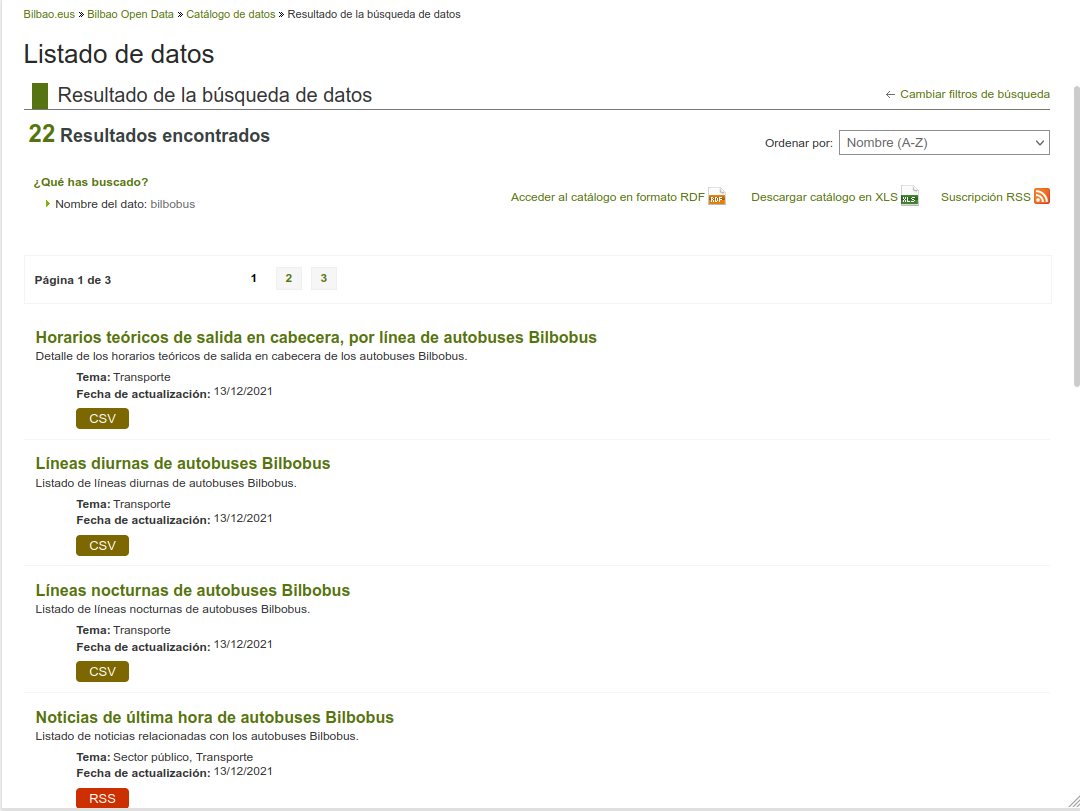
Horarios teoricos de salida
En este ejemplo, los horarios de salida se pueden consultar en la coleccion de datos publicada en http://www.bilbao.eus/aytoonline/jsp/opendata/bilbobus/od_horarios.jsp?idioma=c&formato=csv&tipo=cabecera
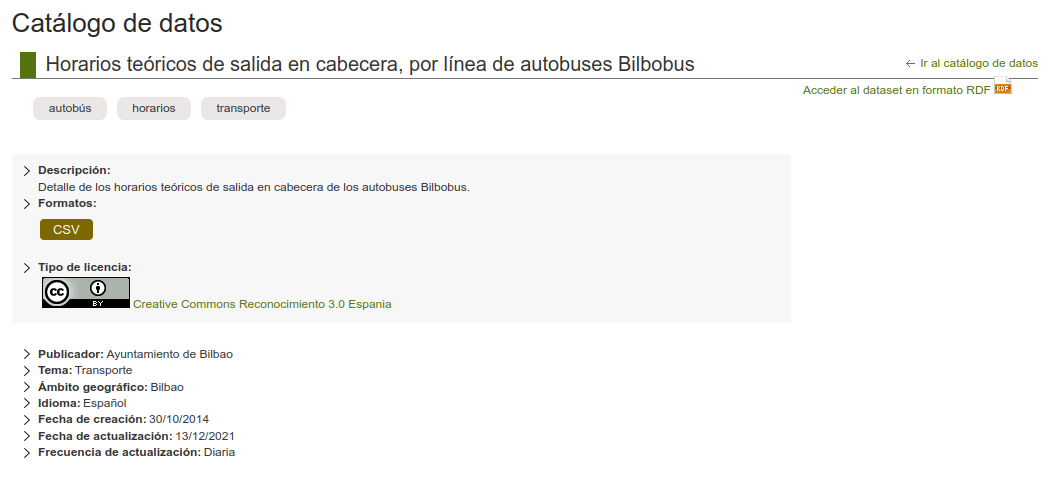
- Descripción: Detalle de los horarios teóricos de salida en cabecera de los autobuses Bilbobus.
- Formatos: CSV
- Publicador: Ayuntamiento de Bilbao
- Tema: Transporte
- Ámbito geográfico: Bilbao
- Idioma: Español
- Fecha de creación: 30/10/2014
- Fecha de actualización: 13/12/2021
- Frecuencia de actualización: Diaria
Acceso en formato RDF: también se puede acceder al dataset en formato RDF mediante la URL https://www.bilbao.eus/opendata/es/catalogo/dato-bilbobus-horarios-teoricos-salida-cabecera/rdf
A través de este dataset, deberiamos ser capaces de conocer los horarios de salida de las cabeceras de todas las lineas disponibles. Veamos si el fichero CSV descargado tiene alguna información extra. Para ello usaremos el comando head
| |
Estamos de suerte, este fichero CSV descargado SI que contiene, al menos, el nombre de cada columna, lo que nos puede dar pistas sobre que es lo que significa cada dato. En otros ficheros o datasets, no habrá esta información, con lo cual tendra que deducirse con dificultad.
Información disponible en el dataset: las columnas
- Temporada
- Codigo linea
- Descripcion linea
- Tipo dia
- Sentido
- Horas de salida
Analizando los datos y su tipo
Ahora que ya sabemos el nombre de cada columna, el siguiente paso es conocer que tipo de dato alberga. Como esta información no se ha definido en ningún sitio por el publicador del dataset, tendremos que deducirlo, de nuevo. Para ello, volvemos a usar el comando head para ver las primeras lineas del dataset CSV.
| |
Te has fijado?
Otra piedra más en el camino. El fichero original tiene una codificación de los datos que no soporta los acentos/tildes del castellano, con lo cual es otra cosa que tenemos que corregir antes de empezar a procesar los datos.
Vamos a validar la hipotesis. Para conocer la codificación o encoding del fichero actual, podemos usar el comando file de la siguiente manera:
| |
ISO 8859-1 es una norma de la ISO que define la codificación del alfabeto latino, incluyendo los diacríticos (como letras acentuadas, ñ, ç), y letras especiales (como ß, Ø), necesarios para la escritura de las siguientes lenguas originarias de Europa occidental: afrikáans, alemán, español, catalán, euskera, danés, escocés, feroés, , francés, gaélico, gallego, inglés, islandés, italiano, neerlandés, noruego, portugués y sueco.
También conocida como Alfabeto Latino n.º 1.
En efecto, detecta que el fichero esta codificado como iso-8859-1, pero por alguna razón los caracteres con tildes usados no corresponden con la especificación ISO y se muestran como �.
Procesando el fichero CSV
Ahora que el fichero ya es legible, para el proposito de integrar en un futuro el contenido en una aplicación web, vamos a convertir el fichero CSV a formato JSON. Para ello, podemos hacerlo manualmente, o usar alguna herramienta online como https://csvjson.com/csv2json. El resultado de la conversión será algo similar a lo siguiente
| |
Pero todavía se necesita procesar el JSON resultado para eliminar toda aquella información que no aporta valor y formatearlo correctamente.
Por ejemplo, se puede convertir al siguiente modelo JSON
| |
Y tener las siguientes mejoras:
- Los nombres de las variables JSON son todas minusculas, siguiendo el estandar.
- Las horas de salida se han convertido de formato texto (String) a un formato de lista, y así poder iterar sobre ellas o realizar busquedas en caso de que sea necesario.
Este proceso se tiene que repetir con toda la información original antes de poder usar los datos y extraer su valor.
Conclusiones
Como ves, el que los datos de un determinado servicio estén publicados no quiere decir que sean procesables. Es necesario un trabajo previo, y más aun cuando no se tienen pistas de cómo está modelada la información. En este post hemos seleccionado un dataset facil de entender, pero te puedes encontrar otros que te pongan el trabajo más dificil, para muestra un botón.
Referencias
- https://www.bilbao.eus/opendata/es/catalogo/dato-bilbobus-horarios-teoricos-salida-cabecera
- https://www.bilbao.eus/opendata/es/catalogo/dato-bilbobus-horarios-teoricos-salida-cabecera/rdf
- https://www.bilbao.eus/opendata/es/catalogo
- https://www.bilbao.eus/opendata/es/terminos-de-uso
- https://csvjson.com/csv2json
Suscríbete, haz una donación o hazte premium
💬 Comparte!!
¡Gracias por leer esto y espero que hayas encontrado la información útil! Si tienes alguna duda no tardes en escribirme un comentario más abajo. Y si quieres ver más contenido, sólo házmelo saber y comparte este post con tus colegas, compañeros de trabajo, amigos, etc.